

AI 모델을 학습시키는데, GPU는 며칠째 풀가동인데 성능 그래프는 좀처럼 안 오르는 경험, 한 번쯤 해보셨을 거예요. 데이터를 더 부어볼까, 모델을 더 키워볼까 고민하다 보면 어느새 학습 비용만 눈덩이처럼 불어나 있죠.
많은 분이 이럴 때 '모델이 부족한가' 아니면 '데이터가 더 필요한가'를 먼저 떠올려요. 그런데 최근 AI 연구의 무게중심은 전혀 다른 곳을 가리키고 있어요. 모델도, 데이터의 양도 아닌 — 가지고 있는 데이터를 어떻게 다루느냐가 성능을 가르는 진짜 변수라는 거죠.
이번 글에서는 'AI를 더 똑똑하게 만드는 법'이 어떻게 바뀌고 있는지, 그 변화를 한곳에 정리한 DataFlex라는 프레임워크가 무엇을 보여줬는지, 그리고 그 모든 게 왜 결국 GPU 인프라 이야기로 이어지는지 함께 짚어볼게요.
AI를 더 똑똑하게 만드는 법이 바뀌고 있어요
지난 10년간 AI 발전의 공식은 단순했어요. 모델을 더 크게, 데이터를 더 많이. 신경망의 연결 수(파라미터)를 늘리고 학습 데이터를 늘리면 성능이 따라 올랐죠. 이런 접근을 모델 중심(model-centric) AI라고 불러요. 데이터는 그저 '많을수록 좋은 연료' 취급이었고, 경쟁의 초점은 모델 구조와 규모에 있었어요.
그런데 이 공식에 균열이 생기기 시작했어요. AI 분야의 대표적 인물인 앤드류 응(Andrew Ng)은 몇 해 전부터 정반대의 메시지를 던지고 있어요. 더 나은 모델을 좇기보다, 모델은 고정해 두고 데이터의 품질을 끌어올리는 데 집중하라는 거예요. 그는 이 전환을 두고 지난 10년간 일어난 딥러닝으로의 전환만큼 중요하다고 말했을 정도예요. 관련 인터뷰는 Fortune 보도에서 확인할 수 있어요.
이 흐름을 데이터 중심(data-centric) AI라고 불러요. 핵심 질문 자체가 바뀌었어요. "모델을 어떻게 튜닝해서 성능을 올릴까"가 아니라, "데이터를 어떻게 체계적으로 바꿔서 성능을 올릴까"로요. Scale의 분석은 데이터를 한 번 전처리하고 끝내는 게 아니라, 학습 과정 내내 계속 다듬어야 할 대상으로 봐야 한다고 정리해요.
왜 하필 지금일까요?
두 가지 현실이 동시에 작용하고 있어요. 첫째, 무작정 데이터를 더 넣는 방식이 한계에 부딪혔어요. 인터넷의 양질 텍스트는 이미 거의 다 긁어 쓴 상태고, 잡스럽고 중복된 저품질 데이터까지 섞어 넣으면 오히려 학습을 방해해요. 그래서 질문이 '얼마나 많이'에서 '무엇을, 어떻게'로 옮겨간 거예요.
둘째, 학습 비용이 천문학적으로 커졌어요. 큰 모델 한 번 학습에 막대한 GPU 시간이 들어가는데, 쓸모없는 데이터에 연산을 낭비하는 건 곧 돈을 태우는 셈이에요. 같은 결과를 절반의 데이터로 낼 수 있다면 그 자체가 비용 절감이고요. Scientific Reports에 실린 연구도 데이터 중심 접근이 성능과 효율 양쪽을 동시에 개선한다는 점을 짚고 있어요.
정리하면, AI 경쟁의 축이 '더 큰 모델'에서 '더 똑똑한 데이터 활용'으로 이동하고 있다는 거예요.
같은 모델인데 데이터만 바꿨더니 성능이 올랐어요
이게 단순한 주장이 아니라는 걸 보여주는 실험들이 쌓이고 있어요. 최근 공개된 DataFlex 연구는 모델은 그대로 둔 채, 학습에 쓸 데이터를 똑똑하게 골라주는 것만으로 성능이 어떻게 달라지는지를 정면으로 검증했어요. 두 종류의 모델, 그러니까 비교적 큰 미스트랄(Mistral-7B)과 더 작은 라마(Llama-3.2-3B)를 같은 조건에서 비교했죠.
결과는 분명했어요. 가진 데이터를 전부 다 쓴 기본 방식보다, 도움이 되는 데이터만 엄선해서 쓴 방식이 일관되게 더 좋은 성적을 냈어요. 큰 모델에서는 종합 시험 점수(MMLU)가 39.4%에서 45.2%로 약 5.8%포인트 올랐죠. 문제집을 통째로 푸는 것보다, 엄선된 핵심 문제만 푸는 게 더 효율적이라는 이야기와 같아요.
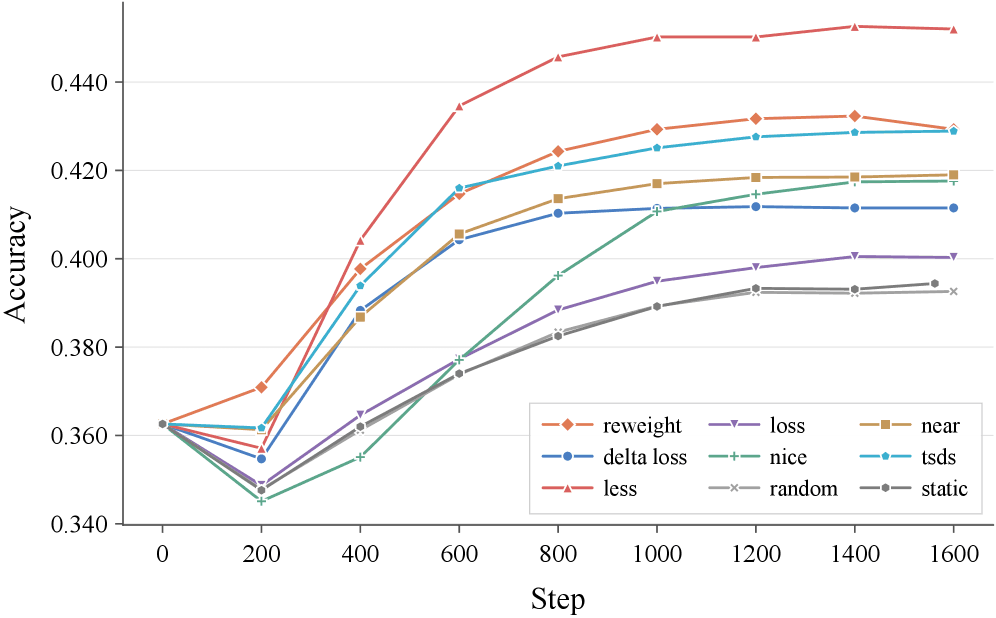
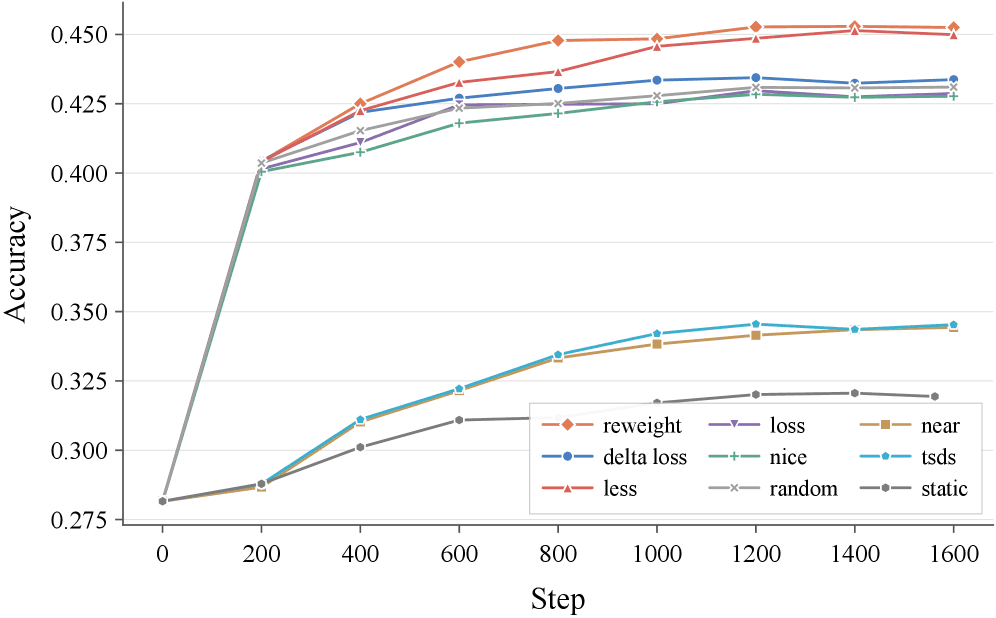
[데이터 선택 전략별 학습 단계에 따른 MMLU 정확도 곡선, 동적 선택 방식들이 전체 데이터 학습(static)을 일관되게 앞서는 그래프 (논문 Figure 3, Mistral-7B / Llama-3.2-3B)]
특히 흥미로운 건 모델 크기에 따른 차이였어요. 작은 모델일수록 이 효과가 더 컸거든요.
작은 모델은 전체 데이터를 다 주면 31.9%에 머물렀지만, 데이터를 똑똑하게 골라주자 45%를 넘었어요.
머리가 아주 좋은 학생은 아무 교재나 줘도 알아서 잘하지만, 평범한 학생일수록 좋은 교재를 골라주는 게 결정적이라는 뜻이에요. 자원이 넉넉지 않은 팀일수록 데이터 전략의 가성비가 높다는 신호이기도 하죠.
또 하나 눈에 띈 건, 작은 모델에서는 학습 도중 실시간으로 데이터를 고르는 방식이 미리 정해두는 방식을 뚜렷이 앞섰다는 점이에요. 모델이 작을수록 '지금 이 모델에게 무엇이 필요한가'를 그때그때 판단해주는 게 더 중요했던 거죠. 자료를 골라내는 것뿐 아니라, 모델이 어려워하는 샘플에 비중을 더 실어주는 방식이 가장 높은 점수를 낸 경우도 있었어요. 결국 '무엇을 어떻게 다루느냐'의 여러 갈래가 모두 효과를 보인 거예요.
데이터를 다루는 세 가지 방법
"데이터를 잘 다룬다"는 건 막연하게 들릴 수 있어요. 하지만 실제로는 크게 세 갈래로 나뉘어요. 학생을 가르치는 데 빗대면 이해가 쉬워요. 그리고 또 하나의 축이 있는데, 이 판단을 학습을 시작하기 전에 미리 정하느냐(오프라인), 아니면 학습이 돌아가는 도중에 실시간으로 바꾸느냐(온라인)예요. 이 두 축을 머릿속에 두면 아래 알고리즘들이 한결 선명해져요.
어떤 자료를 쓸까 — 데이터 선택
가진 자료가 10만 개라고 다 쓰는 게 답은 아니에요. 그중 정말 도움이 되는 알짜배기만 골라 가르치면 시간도 아끼고 성적도 더 잘 나와요. 학습할 데이터의 부분집합을 골라내는 이 방식이 데이터 선택(data selection)이에요. 비용을 줄이면서 성능까지 챙기는, 가장 직관적인 접근이죠.
출처를 어떻게 섞을까 — 데이터 혼합
교재가 여러 종류일 때, 각각을 몇 대 몇으로 섞어 공부시킬지의 문제예요. 대규모 AI 학습에는 웹 텍스트, 책, 코드, 위키백과, 논문 같은 여러 출처가 한꺼번에 들어가는데, 이 비율을 어떻게 잡느냐가 결과를 크게 좌우해요. 국어·영어·수학을 어떤 비율로 공부할지 시간표를 짜는 것과 같아서, 이를 데이터 혼합(data mixture)이라고 불러요.
어디에 더 집중할까 — 데이터 가중치
공부하다 보면 학생이 유독 어려워하거나 중요한 부분이 있어요. 그런 자료에는 비중을 더 두고, 이미 잘 아는 쉬운 자료는 비중을 줄이는 방식이 데이터 가중치(data reweighting)예요. 모델이 어려워하는 샘플에 더 무게를 실어 학습 효율을 끌어올리는 거죠.
실제로 어떻게 작동하나요?
세 방법을 구현한 대표적인 알고리즘이 몇 가지 있어요. 각각 '무엇을 보고 판단하느냐'가 달라서, 그 차이를 알면 전체 그림이 선명해져요. 여기서 한 가지 개념만 미리 잡고 갈게요. 학생이 문제 하나를 풀고 채점받으면 머릿속이 '다음엔 이렇게 생각해야지' 하고 살짝 조정되는데, 그 조정의 방향과 크기를 나타내는 신호가 있어요. 아래에서 계속 등장할 텐데, 어렵게 생각하지 않으셔도 돼요.
LESS — 시험에 도움 되는 자료만 고르기
LESS는 데이터 선택 방법이에요. 핵심 아이디어는 두 가지를 비교하는 거예요. 자료 A를 공부했을 때 학생의 머리가 조정되는 방향, 그리고 우리가 잘 풀고 싶은 시험 문제가 요구하는 조정 방향. 이 둘이 같은 쪽을 가리키면 "자료 A는 시험에 도움이 된다"고 판단해 채택하고, 엉뚱한 방향이면 버려요. 시험에 안 나올 내용만 잔뜩 공부하는 헛수고를 막는 셈이죠.
중요한 건 LESS가 학습 도중에 계속 판단을 갱신하는 온라인 방식이라는 점이에요. 학생의 머리는 공부하면서 계속 바뀌니까요. 그래서 일정 간격마다 데이터 선택을 다시 한 번 점검해요. 실제 실험에서도 LESS는 전체 데이터를 다 쓴 기본 방식을 가장 큰 폭으로 앞섰어요.
DoReMi — 예비 학습으로 비율 미리 정하기
DoReMi는 데이터 혼합 방법이고, 세 단계로 작동해요. 먼저 작은 예비 학생을 기본 비율대로 가르쳐 기준점을 만들어요. 그다음 또 다른 예비 학생을 가르치면서 과목별로 얼마나 더 끙끙대는지를 관찰해요. 유독 못 따라가는 과목은 아직 배울 여지가 많다는 뜻이라, 그런 과목의 비중을 점점 키우죠. 마지막으로 이렇게 알아낸 최적 비율을 고정해서 진짜 큰 모델을 가르쳐요.
여기서 핵심은 예비 학생으로는 작은 모델을 쓴다는 거예요. 작은 모델로 싸게 비율을 알아낸 뒤 큰 모델에 적용하니, 비용 대비 효과가 좋아요. 비율을 학습 전에 미리 확정하는 오프라인 방식이라, 한번 정해지면 학습 도중엔 바뀌지 않는다는 특징도 있고요.
ODM — 학습하면서 실시간으로 비율 조정하기
ODM도 데이터 혼합 방법인데, DoReMi와 달리 예비 학생이 필요 없어요. 한 번의 학습 과정 동안 과목 비율을 실시간으로 조정하는 온라인 방식이거든요. 슬롯머신 여러 대 중 어느 게 돈을 잘 주는지 당겨보며 알아내듯, "이 과목을 공부했더니 학습 효과가 컸네, 비중 늘리자"를 반복해요.
이 탐색적인 성격 덕분에 ODM은 양은 적지만 알찬 전문 과목을 잘 챙겨요. 논문·코드·책처럼 주류 데이터에 묻혀버리기 쉬운 비주류 양질 자료를 놓치지 않는다는 강점이 있죠.
세 알고리즘을 한눈에 비교하면 이래요.
구분 | LESS | DoReMi | ODM |
무엇을 | 자료 선택 | 과목 비율 | 과목 비율 |
언제 결정 | 학습 중 (온라인) | 학습 전 (오프라인) | 학습 중 (온라인) |
예비 모델 | 불필요 | 필요 (작은 모델) | 불필요 |
강점 | 시험 목표에 직접 정렬 | 주류 과목 개선 | 비주류 전문 과목 발굴 |
흩어져 있던 방법들을 하나로 묶은 시도
이 흐름이 뜨거워지면서 전 세계 연구자들이 수많은 기법을 쏟아냈어요. 그런데 바로 그게 문제가 됐어요. 기법마다 제각각의 코드로, 서로 다른 환경에서 만들어진 탓에 "이 방법이 저 방법보다 정말 나은가"를 공정하게 비교하기조차 어려웠거든요. 칼은 A사 규격, 도마는 B사 규격, 냄비는 C사 규격이라 서로 안 맞는 주방 같은 상황이었죠.
최근 공개된 DataFlex라는 프레임워크는 이 문제를 정면으로 겨냥했어요. 데이터 선택·혼합·가중치 세 가지를 하나의 통합 도구로 묶고, 기존에 널리 쓰이던 학습 도구(LLaMA-Factory)에 끼워 넣기만 하면 되도록 설계했어요. 멀쩡한 자동차를 그대로 두고 엔진 부품 하나만 더 좋은 걸로 갈아 끼우는 방식이라, 쓰던 사람도 설정 몇 줄만 더하면 바로 쓸 수 있어요. 코드는 GitHub 저장소에 공개돼 있어요.
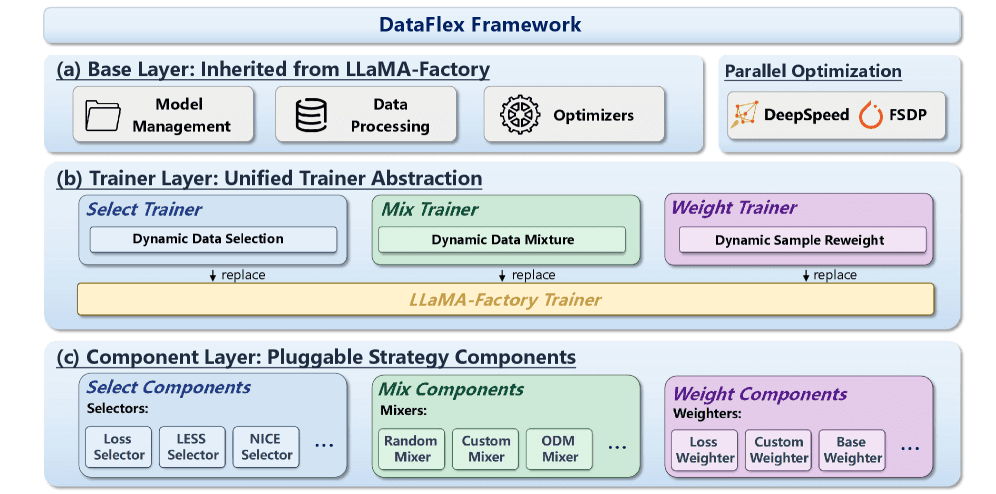
[DataFlex의 3계층 아키텍처 — 기존 학습 프레임 위에 데이터 선택·혼합·가중치 전략을 끼워 넣는 구조 (논문 Figure 1)]
실제로 DataFlex 안에는 데이터 선택 알고리즘 일곱 가지, 혼합 두 가지, 가중치 한 가지가 같은 인터페이스로 들어가 있어요. 덕분에 처음으로 여러 방법을 같은 잣대로 나란히 견줄 수 있게 됐죠. 학계가 이 주제를 표준화할 단계에 이를 만큼 데이터 중심 AI가 무르익었다는 신호로도 읽혀요. 자세한 내용은 arXiv에 공개된 논문에서 볼 수 있어요.
큰 모델일수록, 데이터 비율의 묘가 더 살아나요
DataFlex로 데이터 혼합도 정면으로 실험했어요. 웹·코드·책·논문·위키백과 등 일곱 갈래로 이뤄진 대규모 학습 데이터(SlimPajama)를 두고, 기본 비율 그대로 학습한 경우와 DoReMi·ODM으로 비율을 최적화한 경우를 비교했죠. 결과는 두 방법 모두 기본 비율을 앞섰어요. 종합 시험 점수도, 언어 모델의 기본기를 보는 지표(혼란도)도 함께 좋아졌고요.
흥미로운 건 두 방법의 색깔이 달랐다는 거예요. DoReMi는 데이터에서 절반 넘는 비중을 차지하던 웹 텍스트의 지배력을 54%에서 34%로 낮추고, 그동안 적게 쓰이던 책·위키백과·전문 Q&A의 비중을 끌어올렸어요. 반면 ODM은 실시간 탐색을 통해 논문·코드·책처럼 양은 적어도 밀도 높은 전문 영역을 더 적극적으로 발굴했죠.
그리고 결정적인 한 가지. 학습 규모를 키울수록 이 효과가 더 커졌어요.
학습 데이터를 30B 규모로 키우자, 기본 비율 방식은 어떤 영역에서도 더 이상 1등을 차지하지 못했어요.
다시 말해, 데이터를 더 많이, 더 크게 돌릴수록 '비율을 똑똑하게 짜는 일'의 가치가 오히려 더 도드라진다는 뜻이에요. 그런데 이 30B 규모 실험은 GPU 한두 대로는 어림도 없어서, 서른두 개의 GPU를 네 대의 서버에 나눠 묶어 돌렸어요. 학습 규모를 키운다는 건 곧 더 많은 GPU를 동시에 묶어 돌린다는 의미이기도 한 거죠. 자연스럽게 이야기는 인프라로 넘어가요.
그런데 이게 왜 GPU 인프라 이야기일까요?
여기까지 보면 데이터 중심 AI는 순수하게 소프트웨어 이야기처럼 들려요. 하지만 실제로 돌려보면, 이 방법들은 GPU 인프라와 아주 깊게 맞물려 있어요. 바로 이 지점이 응용을 다루는 분들이 놓치기 쉬운 부분이에요.
데이터를 고르는 데도 여러 대의 GPU가 필요해요
앞서 LESS가 "학생의 머리가 조정되는 방향"을 본다고 했죠. 이 신호를 인프라 용어로는 그래디언트(gradient)라고 불러요. 문제는, 큰 모델은 한 대의 GPU에 다 들어가지 않아서 여러 대에 쪼개어 학습한다는 점이에요. 이렇게 작업을 여러 장비에 나눠 진행하는 방식을 분산 학습이라고 하는데, 여러 공장이 같은 제품을 나눠 만드는 모습을 떠올리면 돼요.
그런데 데이터를 고르는 데 필요한 신호가 이 여러 공장에 조각조각 흩어져 있으면, 판단을 내리려면 흩어진 퍼즐 조각을 다시 맞춰야 해요. DataFlex가 자랑하는 기술 중 하나가 바로 이거예요. 여러 GPU에 분산된 조각들을 모아 전체 신호를 복원하고, 여러 대의 장비를 동시에 가동해 처리하죠. 실제로 한 작업을 GPU 한 대에서 여덟 대로 늘리자 처리 시간이 약 57% 줄었어요. 다시 말해, 데이터를 똑똑하게 고르는 일조차 탄탄한 멀티 GPU 환경 위에서만 제대로 굴러간다는 거예요. 그래서 이런 방법을 제대로 쓰려는 도구일수록, 처음부터 여러 대의 GPU를 동시에 묶어 쓰는 것을 전제로 만들어져요.
비용을 줄이려면, 역설적으로 인프라가 받쳐줘야 해요
데이터 중심 접근의 매력은 "더 적은 데이터로 같은 성능"이에요. 학습에 들어가는 GPU 시간이 줄면 곧 비용 절감으로 이어지죠. 하지만 그 절감을 얻으려면, 데이터를 고르고 섞고 가중치를 매기는 과정 자체가 GPU 위에서 돌아가야 해요. 신호를 모으고 비율을 계산하는 일이 모두 연산이거든요.
그래서 DataFlex도 이 부담을 의식해서 설계됐어요. 무거운 신호 계산은 매 순간이 아니라 일정 간격으로만 하고, 한 번 내린 판단을 일정 기간 재사용하며, 굳이 정밀한 신호가 필요 없을 땐 더 가벼운 지표로 대신하도록 했죠. 데이터 전략으로 아낀 이득이 그 전략을 돌리는 비용에 도로 잡아먹히지 않게 한 거예요. 이런 최적화 역시 결국 여러 GPU를 어떻게 묶고 운영하느냐와 맞닿아 있어요.
결국 그림은 이래요. 데이터 전략으로 큰 비용을 아끼려는 팀일수록, 그 전략을 안정적으로 돌릴 수 있는 여러 대의 GPU를 묶은 인프라가 필요해요. 단순히 GPU 한 장을 더 사는 문제가 아니라, 여러 장비를 효율적으로 연결하고 운영하는 구성의 문제로 넘어가는 거죠.
데이터 중심 AI는 'GPU를 덜 쓰는 법'처럼 보이지만, 실제로는 'GPU를 제대로 묶어 쓰는 법'을 요구해요.
그래서 앞서 본 "작은 모델일수록 데이터 전략의 효과가 크다"는 발견이 더 의미 있어요. 거대한 모델과 무한한 예산이 없어도, 잘 구성된 GPU 인프라 위에서 데이터를 똑똑하게 다루면 충분히 경쟁력 있는 결과를 만들 수 있다는 뜻이니까요.
정리하자면
AI를 더 똑똑하게 만드는 길이 '더 큰 모델'에서 '더 똑똑한 데이터 활용'으로 옮겨가고 있어요. 데이터를 고르고, 섞고, 비중을 조절하는 것만으로 같은 모델의 성능이 일관되게 올라간다는 게 여러 실험으로 확인됐고, 특히 학습 규모가 커질수록 그 효과가 더 또렷해졌죠. 흩어져 있던 방법들을 하나로 묶은 DataFlex 같은 시도까지 등장하면서, 이 흐름은 이제 연구실의 실험을 넘어 표준화 단계로 들어서고 있어요.
하지만 이 모든 전략의 바닥에는 결국 GPU 인프라가 있어요. 데이터를 고르는 일도, 비율을 최적화하는 일도, 비용을 아끼는 일도 여러 대의 GPU를 효율적으로 묶어 돌릴 때 비로소 제값을 해요. 소프트웨어처럼 보이는 흐름이, 실은 하드웨어 구성의 문제로 되돌아오는 셈이에요.
데이터를 다루는 방식이 정교해질수록, 그 정교함을 받쳐줄 인프라의 중요성도 함께 커지고 있어요.
출처 — 이 글은 아래 자료를 바탕으로 작성했어요. 본문의 비유와 예시는 4-5층 응용 개발자의 이해를 돕기 위한 것으로, 실제 알고리즘의 세부 동작과는 차이가 있을 수 있어요.
Hao Liang 외, "DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models" (Peking University 외, 2026), arXiv:2603.26164. 본문 속 정확도·혼합 비율·학습 시간 수치 및 아키텍처 그림은 이 논문에서 인용했어요.
데이터 중심 AI 전반의 배경은 앤드류 응(Andrew Ng)의 데이터 중심 AI 논의(Fortune, 2022), Scale의 model-centric에서 data-centric으로의 전환 분석, Scientific Reports의 관련 연구를 참고했어요.








